


自己搞一个Linux系统调用的一点记录
自己搞一个Linux系统调用的一点记录
项目的缘起是同院不同专业后辈的大作业。我看了一下作业的内容,发现涉及到的深度比我专业之前该课程涉及的深度还要深,甚奇之。
开始着笔写文章的时候已经折腾了24个小时,而我中间仅仅睡了不到五个小时,所以急需记录一下涉及到的问题,以免突然倒地之后忘记(
作业的题目是“在Linux内核中添加一条自己的系统调用,按照某规则显示个人学号的后X位”,有意思的是题目中示例是16年的学号,而且据说提供的示例代码基于Ubuntu 10.04,至少是2010年之前的事情,所以如果现在还做不到吃透这道题多少有些失败。这也是我和它杠上的原因。
我寻思着与其看那上古的 Ubuntu 10.04 代码,然后不知所云地搞出一个知其然而不知其所以然的玩意,不如用近几年的 Ubuntu 和新一点的内核开刀。
值得一提的是Robert Love在他的著作Linux Kernel Development提到not implement a system call,并且给出了非常详实的理由,所以最好不要通过乱改系统的系统调用表实现自己要实现的功能,否则在kernel.org更新内核之后,自定义的内核和用户空间程序都会变成不兼容的废物,不过这是课程实验无需上纲上线(
于是,在开写这篇文章之后又折腾了两三天。最后估计花了得有四五天时间,算作96个小时,终于搞出了一个比较满意的结果(但不能算完全满意)。
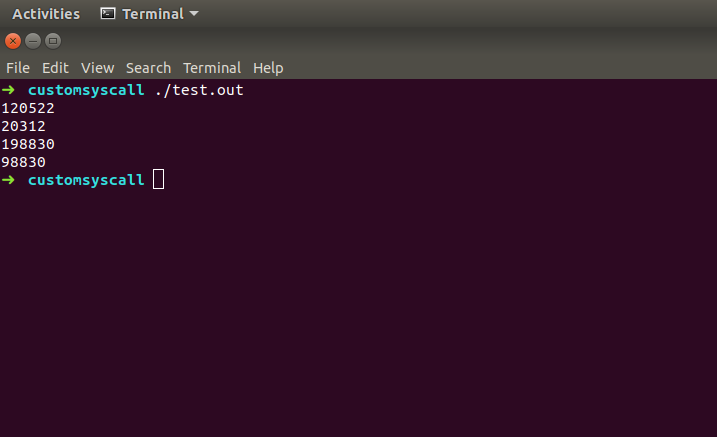
记录一下踩过的坑。
排坑指南
没遇到坑之前可以跳过这部分直接看后面的“步骤”一节
点击目录图标,待目录弹出后点击“步骤”即可
使用无图形的系统还是有图形化界面的系统
我的建议是用有图形化的,因为这涉及到是否有方便的面向项目目录编辑工具,是否有多国语言支持,是否能开出数个模拟终端用于不同的工作,是否有一个能随时用于查找问题的浏览器等和开发速度有关的问题。
尽管图形界面会带来额外的开销,额外的不稳定性,额外的库需求。
但是如果懒得搞ssh的话,一个良好的人机界面值得这些。
内核版本问题
首先是版本的问题。我日常开发用的是Ubuntu 20.04.4 LTS on
WSL,uname -r或者neofetch一下可以得知内核版本为”4.4.0-18362-Microsoft”,于是我理所当然地以为Ubuntu的官方发行版内核版本也在4.x左右,甚至特意挑选了18.04
LTS这个较老的版本(其实本来想用16.04
LTS,但是镜像站的16.04已经404了)。
这造成了第一个悲剧:我下载了一份4.15.3的源码埋头开始了工作。
Ubuntu 18.04.6 LTS 最新的内核版本为 5.4.0-113,众所周知,旧系统可以兼容新内核,但新系统基本不能兼容老内核,这是第一个雷。
这个雷导致的后果是,4.15.3的内核无法启动 Ubuntu 18.04LTS 的图形界面,这使得原来指向虚拟终端的文件指针无法使用,在这种情况下必须改成指向实际终端的文件指针。
最后完成的版本使用的内核版本是5.18.2,高于Ubuntu 18.04.6 LTS所使用的5.4.x,这样就能成功运行Ubuntu 18.04.6LTS的大多数功能了。
磁盘空间问题
然后是第二个问题,在创建虚拟机磁盘文件时,需要选择一个合理的磁盘空间,我错误估计了这个过程所需要的磁盘空间。按自己以往的经验,单个Ubuntu虚拟机分个20GiB足矣,考虑到也许、可能不够,我又加了10GiB,“添加的数量已经是原本预计数量的1/2了,总数30GiB,对于一个没有其他任务的系统来说已经很多了吧”。
这就是想当然了。
第二个悲剧:为虚拟机分配的30GiB磁盘空间不足以容纳Ubuntu 18.04.6 LTS系统自身和编译内核过程中产生的文件。编到一半,Low Disk Space了,编到最后,No enough space on disk。
按照目前的统计,64GiB硬盘空余30GiB,因此至少得预留35GiB才能保证不出问题,稳妥起见,40-60GiB是比较合适的,当然这仅仅适用于在18.04LTS上编译5.18.2的情况。
然而现在发现,磁盘空间不足的问题也是在.config中没有要求不编译大多数用不上的模块导致的,编译前使用make localconfig可以有效地减少磁盘空间占用
性能问题
为虚拟机分配多少CPU和内存合适?我按照默认选择了1核心和1024MiB内存。对于日常使用而言当然是绰绰有余的,但是这不是日常情况。
在经历了在我自己的计算机(4C8T16G)上为虚拟机分配2核心8GiB内存进行编译之后,目前我已经将工作迁移到了另一台实验室公用的计算机上,向虚拟机分配了12核心16GiB内存,make -j12,但是速度依然慢到令人烦躁。
“这就是对生产力工具的性能要求”
依赖工具
编译内核需要,但是可能没有自动安装的工具(或者说软件包和库)包括
列表
flex
lex产生词法分析器的开放源代码版本
Lex读进一个代表词法分析器规则的输入字符串流,然后输出以C语言实做的词法分析器源代码。(https://zh.wikipedia.org/zh-cn/Lex)
flex(快速词法分析产生器,英语:fast lexical analyzer generator)是一种词法分析程序。它是lex的开放源代码版本,以BSD许可证发布。通常与GNU bison一同运作,但是它本身不是GNU计划的一部分。(https://zh.wikipedia.org/zh-cn/Flex%E8%AF%8D%E6%B3%95%E5%88%86%E6%9E%90%E5%99%A8)
bison
Bison is a general-purpose parser generator that converts an annotated context-free grammar into a deterministic LR or generalized LR (GLR) parser employing LALR(1) parser tables.(https://www.gnu.org/software/bison/)
噔!噔!咚! “上下文无关语法” “LR分析法” 这一下给我轰回了编译原理的课堂,让我想起了被文法支配的恐惧
build-essential
这个在linux下做开发都要用到,不必多说
libncurses5-dev
The ncurses (new curses) library is a free software emulation of curses in System V Release 4.0 (SVr4), and more. It uses terminfo format, supports pads and color and multiple highlights and forms characters and function-key mapping, and has all the other SVr4-curses enhancements over BSD curses. SVr4 curses became the basis of X/Open Curses. (https://invisible-island.net/ncurses/announce.html)
一个终端下的图形库,至少在make menuconfig过程中和那个图形化配置菜单有关
openssl和libssl-dev
与加密过程有关,至少安装的时候会涉及到签名问题
zlibc和minizip
与压缩有关的库,内核映像需要压缩
libidn11和libind11-dev
GNU Libidn 库,IETF(互联网工程任务组)IDN(国际化域名)规范的扩展和用于其开发的文件 (https://packages.debian.org/search?keywords=libidn11)
libelf-dev
用于ELF(Executable and Linking Format)开发的库
dwarves
BPF is a technology that allows unprecedented ability to execute custom external code safely inside the Linux kernel in response to various events/hooks. (https://facebookmicrosites.github.io/bpf/blog/2018/11/14/btf-enhancement.html)
如果不装,会在make modules过程中产生有关tmp_vmlinux.btf的错误(如果在linux-x.x.x/config里面设置CONFIG_DEBUG_INFO_BTF=n那就不用装)
一条命令解决(一部分)问题
1 | sudo apt update && sudo apt upgrade && sudo apt install flex bison build-essential libncurses5-dev openssl libssl-dev zlibc minizip libidn11 libind11-dev libelf-dev dwarves |
签名问题
非常坑爹的问题
我再重申一遍,这个问题 非常非常 坑爹!
我打赌这96个小时里至少有60小时浪费在签名导致的无法install从而重新编译一遍上面
坑爹啊!我只是做个实验,为甚么要考虑内核模块加密和签名啊,这是操作系统课程又不是系统恶意攻击防范安全课程。
其实后来发现更多的时间被浪费在了编译一些用不上的内核模块方面(
标红:
| > Should I remove CONFIG_SYSTEM_TRUSTED_KEYS from .config before building |
| > the kernel? I hope not. |
Yes, you must do that. Your custom kernel configuration should be based on the appropriate file provided in linux-source-4.5. These have the CONFIG_MODULE_SIG_ALL, CONFIG_MODULE_SIG_KEY and CONFIG_SYSTEM_TRUSTED_KEYS settings removed so that custom kernels will get modules signed by a one-time key.
在 开 始 编 译 之 前 , 需 要
在.config中置n或置空所有有关CONFIG_MODULE_SIG_ALL
CONFIG_MODULE_SIG_KEY
CONFIG_SYSTEM_TRUSTED_KEYS的选项
另外根据我的判断和实践,与KEY有关的涉及到BLACKLIST和REVOCATION的选项也全部置n或置空
前提系统仅仅作为实验用途。
但是,CONFIG_MODULE_SIG_KEY="certs/signing_key.pem"这一行需要原样保留,不能置空,这指定了自动签名需要用到的文件,如果置空,则会报错。
权限问题
当我尝试在Windows的目录系统中用7-zip解压Linux-5.18.2.tar.xz的时候,提示错误“没有建立链接xxxxx的权限”,我还以为这个打包的内核文件里面有什么特别的权限问题需要处理,以至于我在网上找教程的时候,看到教程中从第一个make clean就开始sudo竟没有半点怀疑。
事实上,编译内核的前几步不需要sudo也不应该sudo————平常随便编译个什么程序需要sudo吗?
只有在涉及到install的时候,因为需要将编译好的文件放到系统目录里面,才需要sudo。
不然呢,在自己家目录下面的工作目录里面创建一大堆只有root才能访问的文件很好玩吗?
步骤
需要修改以实现功能逻辑的文件一共有三个
linux-x.x.x/arch/x86/entry/syscalls/syscall_64.tbl
系统调用表
linux-x.x.x/include/linux/syscalls.h
系统调用服务例程声明
linux-x.x.x/kernel/sys.c 系统调用服务例程定义
修改syscall_64.tbl
在系统调用表中添加系统调用
在”64-bit system call numbers and entry vectors”引导的注释结束之后向下寻找,在”Due to historical design error, certain syscalls are numbered differently”…这一部分开始之前的上面找到最后一个系统调用
5.18.2的最后一个系统调用是450号,sys_set_mempolicy_home_node调用
在其下,按照
number是系统调用号,和入口地址有关,必须是数字,顺着上面往下写即可
abi是通用二进制接口,对于5.18.2的syscall_64.tbl文件,abi的值可以是”common”、“64” 或”x32”之一,我选择”64”
name是该系统调用的名称,稍后在”sys.c”中进行定义的时候需要用到
entry point是系统调用的入口点,稍后在”syscalls.h”中进行声明的时候需要用到
因此最后写入 451 64 customcall sys_customcall
修改syscalls.h
在系统调用服务例程原型声明头文件中声明服务例程的形式。
开头的注释里面写了规则
These syscall function prototypes are kept in the same order as include/uapi/asm-generic/unistd.h. Architecture specific entries go below, followed by deprecated or obsolete system calls.
Please note that these prototypes here are only provided for information purposes, for static analysis, and for linking from the syscall table. These functions should not be called elsewhere from kernel code.
As the syscall calling convention may be different from the default for architectures overriding the syscall calling convention, do not include the prototypes if CONFIG_ARCH_HAS_SYSCALL_WRAPPER is enabled.
于是在这里的最后一行,用于判断其他情况的ifdef之前写入自己的函数声明
1 | asmlinkage long sys_customcall(int tty, int mode, long stuid); |
修改sys.c
这是服务例程的定义实现部分
SYSCALL_DEFINE是一个用于定义系统调用的宏函数,有几个写法,SYSCALL_DEFINE1,SYSCALL_DEFINE2,SYSCALL_DEFINE3,后面的数字代表之前声明中参数的个数,可以是0
1 2 3,而这个宏函数自身的参数则是以下几项
1st. 系统调用名
2nd. 参数1的类型
3rt. 参数1的名称
4th. 参数2的类型
5th. 参数2的名称
… … … …
上面自定义的函数的第一行写作 1
SYSCALL_DEFINE3(customcall, int, tty, int, mode, long, stuid)
而函数体则按照通常的写法,这里注意到上面浏览一下include列表,有包含的头文件就有,没有包含的头文件就没有(废话),而且(重点是)不要自己乱添加,linux的内核态中的程序并非完全兼容C标准库。
这个程序的逻辑部分其实非常简单,在别处稍稍写写,甚至没有怎么调试就可以由输入得到输出了。然而这个实验的重点不在这里。
主要的问题在于我对于内核中的函数并不熟悉,所以不知道用那些函数进行输出,(其实也不知道用哪些函数输入,但是函数需要的数据可以用参数传入所以暂不考虑输入的问题)
首先可以用脚趾排除掉printf的可能性,printf的参数列表没有包括输出的目的地,默认为stdout,对于一个正在某个tty上登入的用户,其stdout是确认的,但是对内核来说并不知道stdout在哪
进一步来说,printf是一个定义在”stdio.h”中的标准输出函数,而”sys.c”的include文件列表中并没有”stdio.h”
能够指定输出目标的是fprintf和sprintf然而查找了一下,fprintf和sprintf也是”stdio.h”中的函数
其中,fprintf用文件描述符定义输出的目标,很可惜文件描述符也是一个用户空间的东西,在内核层面是无法理解的内容
我又试着顺着printf向里找它的实现过程,printf能够一直追溯到vsprintf,然而在往上是宏定义,对于我来说线索到此中断
在第二还是第三天偶然发现了一个叫做printk的函数,这个函数可以以与printf类似的方式向内核输出字符串,它和printf不同之处在于第一个参数,printf的首个参数是一个指向char的指针,而printk的首个参数则是一种很奇特的形式,它由一个整数和一个指向char的指针绑定而成。
比如说
1 | printk(KERN_NOTICE "Hello, world.\n"); |
其中KERN_NOTIC是一个宏定义的整数
这个形式看起来很不美观,虽然能完成任务,但是把同一个输出贴满所有tty……对我来说还是接受不能,用来输出调试信息还行,拿来完成这个实验什么的就算了。
换个思路来考虑,Linux下一切皆文件,所谓的输出到标准输出,也可以理解为写入到标准输出这个文件里,使用文件操作函数也能实现想要的功能。
然而fopen、fwrite也是在”stdio.h”中定义的。
继续向里追溯,write是一个定义在“unistd.h”中的函数,“sys.c”中包含了#include <asm/unistd.h>这一语句,因此似乎是可以使用的。
write(STDOUT_FILENO, msg_str, sizeof(msg_str) *n);
然后编译过程就报错了“implicit declaration ‘write’”
“use of undeclared identifier 'STDOUT_FILENO'”二连(和两次编译花掉的时间)。
其实吧,这里还是图样,即便拿到了STDOUT_FILENO的定义,其实也就是个1(大多数情况),如果真的能用write把一个“1”传进内核,内核又怎么知道往哪输出呢,所以说其实一开始就根本不用考虑这个写法。
接着找到了sys_write这个函数,这次编译成功了(4.15.3),
然而用该版本内核根本无法引导出图形界面,只能看到TTY,还得换输出目标,我折腾了一下,把输出换到/dev/tty1,然后什么都没有拿到
在茫然了很久之后。
我发现我似乎是在忘记了操作系统课程的内容之后进行了一番盲目的尝试浪费了不少时间。
什么是file descriptor?什么是file entry?什么是struct
file?哪个在用户空间,哪个在内核空间?当我在内核中编写一条系统调用的时候,拿到的到底是file
descriptor还是file
entry?int fd是什么?FILE *fp是什么?
把这些全忘了的虫豸,怎么能写好内核呢? (掏出PPK)
所以我得复习一下这些内容,除了翻书之外,网上的一些博客也可以参考一下,有关这个问题例如:
Linux 的 file descriptor 筆記 - Kakashi’s Blog
(网内有人转载了这篇文章,如果上面的链接打不开的话:(转载)Linux的file descriptor笔记)
重点是这张图片:
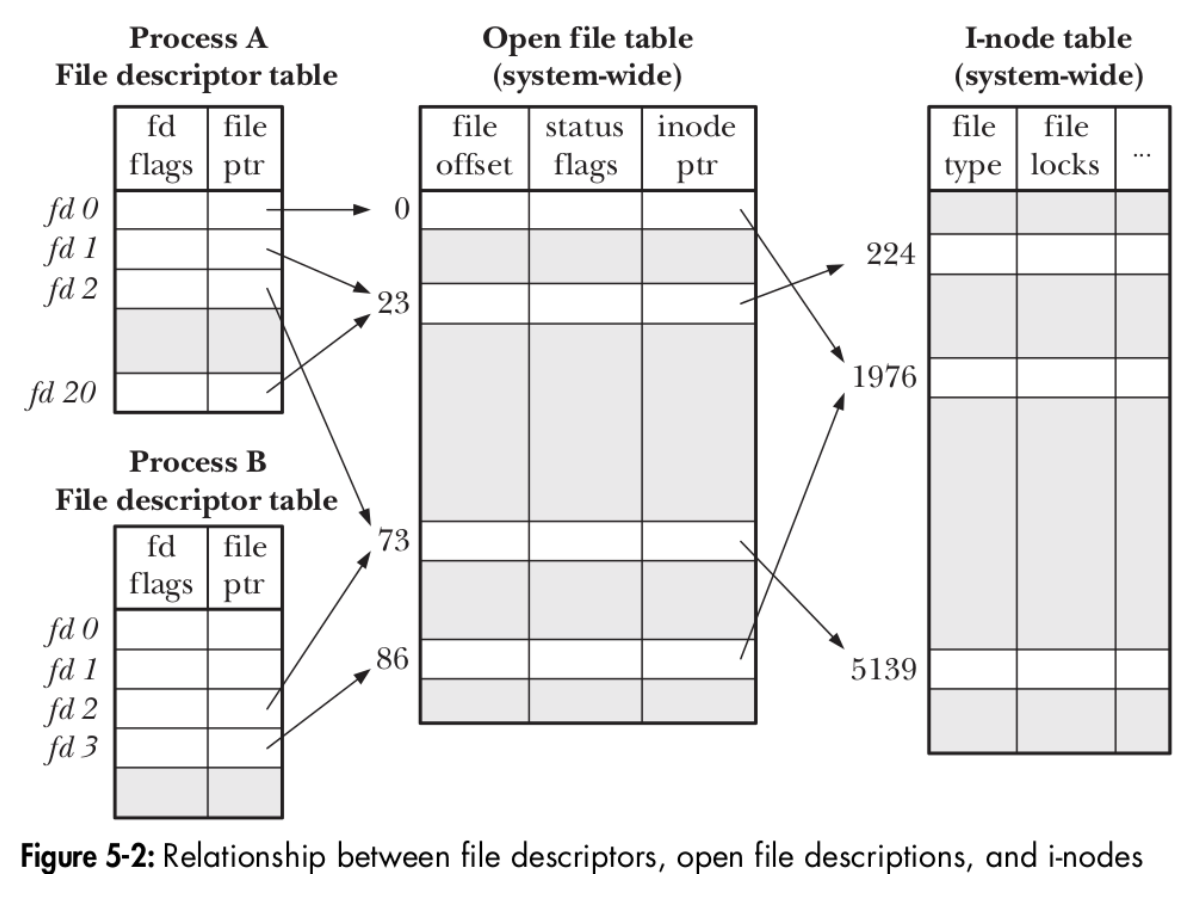
文章里面也提到了lusp_fileio_slides
所以在内核里的时候,对着“file discriptor”磕下去就是死路一条
参考Read/write files within a Linux kernel module中的答案Read/write files within a Linux kernel module#53917617
得知,内核层面的读写文件应当使用filp_open
kernel_read kernel_write
之后我参考了博客Access File in Kernel中的写法,主要是这几行
1 | fp = filp_open(path, O_RDWR | O_CREAT, 0644); |
之后形成了我在这个实验中的代码
1 | struct file* fp; |
这样,最终完成了实验的目标。
P.S. 此外文件指针导致的失败暴露了另一些方面考虑不周的问题,最后我加了一个传入的参数,在服务例程里做了一个分支处理解决了。当然假如程序能得到进一步的改进,在用户空间程序获取当前tty名称封装进参数,在内核空间程序获取从用户空间程序传来的信息,那么就不用考虑“到底是哪个tty”的问题了。
编译和安装
这一步要用到的命令大概有这几种
make mrproper
彻底清理整个目录,在需要将所有结果推倒重来的时候使用,清除掉里面所有可能的不需要的东西,包括.config文件在内,所有文件恢复如初(自己更改的代码文件除外),以准备一次完全重新开始的make
make clean
保留.config,清理中间结果,比如目标文件之类的东西,至少在执行完make mrproper之后是没必要执行一遍make clean的
make config或者make menuconfig
都是用于创建设定编译选项的.config这个文件的命令,后者需要额外的库,并且需要终端至少有一定的宽度否则会报错,但我仍然建议使用后者,就当是为了键盘的Enter键的健康着想吧,或者会用yes也行,if
you like
不过对于.config文件,我目前的建议是make localconfig,按照目前加载的内核配置进行编译,这样可以减少需要编译的模块,大大节省耗时。
2023.04.03更新:在最近的一次针对6.2.9内核的编译过程中发现make
localconfig不可用,找到了一个方法说可以使用make
localmodconfig代替,但是有人警告说这两个命令不太一样,反正我试了是可以生成正常的.config文件的
make 这个就不解释了
2023.04.03更新:写文章的时候忘了提,make的时候可以设定架构,务必记得查询本机的CPU线程数以加快编译速度,此外还有对输出日志重定向,以免打印到屏幕浪费算力,如果目标是amd64,本机CPU有8个线程,日志重定向到上一级的文件中,那么就输入make
ARCH=x86_64 -j8 >
../makekernel.log,这样会加快速度,而且只在屏幕上打印警告和错误,日志可以稍后自行通过其他方式查看
编译模块 1
make modules
安装模块 1
sudo make modules_install
安装内核 1
sudo make install
注意
配置.config的时候会询问是否打开-Werror选项,虽然我平常自己编译程序的时候会常开这个选项,但是这里可以明确说,编译5.18.2内核的时候不要开这个选项折磨自己,因为该版本内核中jffs2_build_xattr_subsystem
od_set_powersave_bias stmmac_request_irq_multi_msi
vhost_scsi_flush这几个函数在某处调用的时候存在warning
一条命令完成编译和安装
善后
自己编译安装的自定义版本内核不能通过预装的自动化包管理工具进行管理。
管理这些内核 可能 需要手动方法。
目前卸载内核的方法参考了:
linux下删除内核 - amanlikethis - 博客园
但是我注意到,在/下执行sudo find -name "linux-4.15.3"之后,在/var/lib/initramfs-tools/+下也发现了和该版本内核有关的文件,既然不用这个版本的内核了,那么删掉应该也没有什么影响。
而同一新版本的内核,只在/boot下发现了冗余的*.old文件,如果新内核可以正常使用,那么也就不留着*.old了
最后sudo update-grub
目前除了手动管理之外,暂时没有发现什么更好的管理工具
后续改进计划
使用ttyname函数从用户空间获取输出目标 (STATUS: FINISHED)
用户空间函数
1 | char *ttyname(int fd); |
定义于 <unistd.h>
提供了获得当前tty名称的功能
假如在用户空间调用该函数,并将获得的字符串压入传参结构体,通过系统调用函数传给内核空间的服务例程,就可以在任意tty下获取输出。
这是一个更加优雅的方案,但是涉及到定义新结构体,在内核空间重新对字符串处理并传给filp函数,以及改变代码之后漫长的编译过程,因此是 to be done 任务。
先保存一个能成功运行的版本。
首先把原本的传参方式改掉,现在使用一个结构体来传参,定义结构体如下:
1 | typedef struct customcallparamentstructure{ |
在用户空间做出以下更改
1 | custompara_t paraS; |
在内核空间做出以下更改
1 | fp = filp_open(paraSp->ttystr, O_RDWR, 0); |
这样就做到了无论正在使用哪种终端,都可以自动选择终端输出字符串
改变内核的版本号码 (STATUS: FINISHED)
compiling - Linux kernel version suffix + CONFIG_LOCALVERSION - Unix & Linux Stack Exchange
在.config的CONFIG_LOCALVERSION处加上自定义字符串,使编译后产生的内核有独特的版本号码字符串,以与其他内核区分。
效果如图

Knighthana
2022/06/10